Agglomerative clustering algorithm in R
Usually when we talk about clustering, we’re going to think about K-means and Hierarchical Clustering, but here we’re going to talk about Hierarchical Clustering. Hierarchical Cluster analysis can be divided into discrete, top-down (DI), which is a method of separating data into detailed clusters, as opposed to Aggolomerative (Bottom-Up Method) (AG), which starts with individual data and binds similar data into clusters.

What the researcher has to think about here is what methodology to approach. You can make a choice after comparing the two approaches. However, in general, AGs perform well when they want to find clusters of smaller units, and DIs perform well when they want to find larger clusters.
Hierarchical clustering is an algorithm (a binary tree configuration of data) that calculates the distance between all two clusters in a given data.
1. Bundle the data at the closest distance together (repeat)
2. Proceed until it eventually merges into one cluster
3. Align with natural hierarchies in the form of Dendrogram.

Linkage method
- Complete: The longest connection method defines the longest distance between two clusters as the intercluster distance.
- Single : Shortest connection, which defines the shortest distance between two clusters as the intercluster distance.
- Ward.D : A method proposed by Ward to merge clusters based on the sum of squared deviations within clusters rather than on the distance between clusters. Define that the loss of information in merging clusters is minimal.
- Ward.D2 : The Ward.D method uses standardized values and uses power values instead of absolute values.
- Average : The mean connection method defines the average distance between all individuals in each cluster.
- Mcquitty: Weighted Pair Group Method with Arithmetic Means (WPGMA), in which two nearest clusters combine to form a single group, the distance from the other clusters is obtained by the arithmetic mean.
- Median: The median distance between clusters is defined as the median of all samples in a cluster.
- Centroid: The distance between two clusters is defined as the distance between the centers of two clusters. Here, s,t represents the center point of each cluster.
Cluster linkage
- single : Use the distance between two clusters between the nearest data
- complete : Use the distance between two clusters between the farthest data
- average : Leverage the average distance between all data in a cluster and all data in another cluster

Clustering algorithm in R
library(cluster)
# use daisy() function to calculate gower distance
gower.dist <- daisy(carAccident[, 2:9], metric = c("gower"))
class(gower.dist)
# Using "complete" linkage - agglomerative
agg_clust_c <- hclust(gower_distance, method = "complete")
plot(agg_clust_c, main = "Agglomerative, complete linkages")
# Using "complete" linkage - divisive
divisive_clust <- diana(as.matrix(gower_distance),
diss = TRUE, keep.diss = TRUE)
plot(divisive_clust, main = "Divisive")
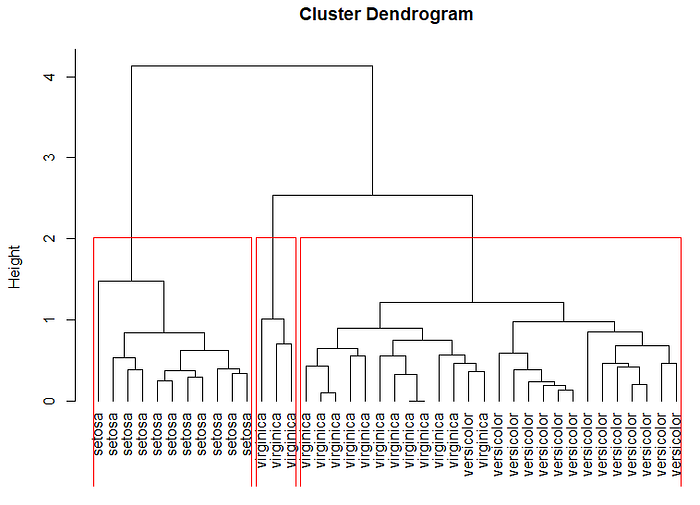
# divide dendrogram into two clusters
rect.hclust(divisive_clust, k=2)
group <- cutree(divisive_clust, k =2)
table(group)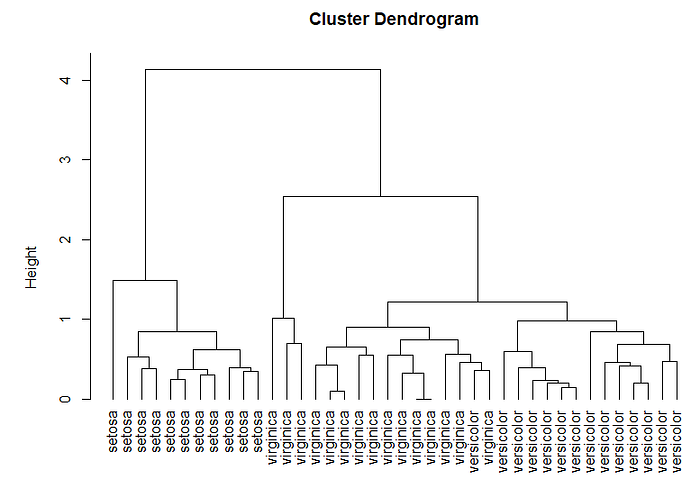
Hierarchical cluster analysis shows cluster analysis results as dendrogram in tree structure format as shown above.
Advantages
- It is easy to examine the structural relationship between the entire clusters
- There is no need to determine the number of clusters in advance
Disadvantages
- Calculation is slow when the data set is very large
- Rearranging data, or excluding several observations, can result in completely different results
- Once an object is assigned to a particular cluster, it can sometimes lead to incorrect cluster results because it has the property of never being included in another cluster again
- Initial classification of outliers distorts the overall structure
Algorithms
- Form n clusters of objects using each object as one cluster
- Summarize the two nearest clusters by calculating the distance between each cluster
- Repeat 2 times to continue merging clusters until all objects become one cluster
- Dist() function is frequently used for distance calculation
- The hclust() function, which combines two nearby clusters, is often used for hierarchical cluster analysis
ref.
